
Recently I did a Proof of Concept (POC) on Azure Databricks and how it could be used to perform an ETL process. This blog with give an overview of Azure Databricks with a simple guide on performing an ETL process using Azure Databricks.
The scenario is to load FIFA World Cup data from an Azure Blob Storage account, using a mix of Scala and SQL to transform the data types, add new columns then load that data into Azure SQL Database all using one Azure Databricks notebook.
I chose to use Scala and SQL to perform these tasks, though they could have easily been accomplished by using other supported languages. This is just one approach to perform an ETL and is not an extensive tutorial on Azure Databricks. Please use some of the reference links provided for further information.
Illustration of the data movement for the scenario.

What is Azure Databricks
Before getting into the ETL activities, let me give you a brief explanation of Azure Databricks.
Azure Databricks is a managed platform based on Apache Spark, it is essentially an Azure Platform as a Service (PaaS) offering so you get all the benefits without having to maintain a Spark cluster. It is fast, scalable cluster service with on-demand workloads, workbook scheduling, supports R, SQL, Python, Scala, and Java and integrated with Azure Active Directory (AAD). For more information, see What is Azure Databricks
Azure Databricks has an interactive workspace that enables collaboration between users and supports the uses of different coding languages (R, SQL, Python, Scala, and Java). They are used to create notebooks and can be mixed & matched to gain the most benefit from each language giving the user the ability to use the language that they are comfortable using. Regardless of the languages used it is still compiled back to Scala in the background.
Azure Databricks is one of the key components to the “modern data warehouse” approach, which brings together all your data in an easily, scalable and interactive way. It supports the other Azure products including Azure Active Directory, Azure Data Factory, Azure Blob Storage, Azure Data Lake, Azure SQL Database, Azure SQL Data Warehouse and so on. For more information, see Modern Data Warehouse
Prerequisites
There are some prerequisites before starting the ETL activities:
- You will need an active Azure Blob Storage account with the dataset **WorldCupMatches.**csv stored. You can download the CSV file from Kaggle.com
- You will need to create an Azure SQL Database, this can be accomplished by using the Azure Portal.
- You will need to create an Azure Databricks Workspace and Cluster, this can be accomplished by using the Azure Portal.
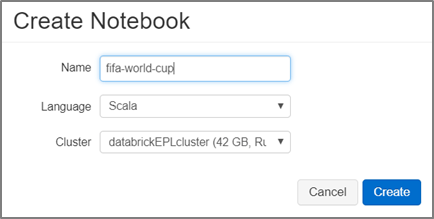
Create Notebook
In Azure Databricks Workspace create a new Notebook, using the Scala language and specify the Cluster it needs to use.
Access Blob Storage Account
Before extracting the dataset from the blob storage account, you need to give Databricks access to the storage account. You can do this by mounting the storage account to Databricks Filesystem (DBFS) where it stores the data on the Cluster’s filesystem, with the ability to reuse the storage account multiple times for other notebooks in the same cluster.
An alternative approach is to give direct access to the storage account though there are limitation on this approach and is not covered in this blog.
Using Scala, you can mount the storage account with DBFS:
- You will need to define the Blob Container, Storage Account and provide the Storage Account Access Key.
- You can define a mountPoint destination "/mnt/mypath", which will allow you to use the storage account without the full path name.
- Once the code is executed it will mount the storage account to the filesystem, therefore it does not need to be executed again. The code can be commented out (using forward slash //) or deleted.
%scala
dbutils.fs.mount( source = "wasbs:// <Container Name>@<Storage Account Name>.blob.core.windows.net/", mountPoint = "/mnt/mypath", extraConfigs = Map("fs.azure.account.key. <Storage Account Name>.blob.core.windows.net" -> "<Storage Account Access Key>"))
Create Temp Tables based of CSV file
You can now extract the dataset from the blob storage account and create a temporary (temp) table using SQL statement, this is used to stage the data.
When working with multiple languages in a notebook you must define the language you are going to use, as we are jumping from the Scala to SQL in our notebook you need to specify the language magic command %sql at the beginning of the code. For more information, see Mixing languages.
%sql
DROP TABLE IF EXISTS tmpWorldCupMatches;
CREATE TABLE tmpWorldCupMatches USING csv OPTIONS ( path "/mnt/mypath/WorldCupMatches.csv", header "true", mode "FAILFAST" );
Now that the data is in a temp table, you can query and change the data to meet your needs then store this into a table using SQL statement.
Databricks uses Spark SQL which allows you to structure data inside Spark, therefore there are some limitations as not all SQL data types and functions are compatible or available. Some basic elements like “double” quotes, ‘single’ quote and [square brackets] are either not compatible or do not behaviour in the same way as they do in standard SQL statement.
The ` accent key is used to define a column with spaces and to change a column name as square brackets and single quotes are not compatible for these function. Single and double quotes can be used to define a string values within the SQL statements otherwise they are not compatible.
Change Data Types
Change the data types of the columns using the CAST function to their appropriate data types as they are all defaulted to “String” data type. The following code will return the metadata for the tmpWorldCupMatches temp table.
%sql
DESCRIBE tmpWorldCupMatches
Create New Columns
Add a couple of new columns to split the date and time, unfortunately the datetime data type is not supported in Spark SQL. So, to achieve our goal you will need to CAST datetime column to TIMESTAMP and then extract just the date and time part.
,TO_DATE(CAST(UNIX_TIMESTAMP(`Datetime`, 'dd MMM yyyy - HH:mm' ) AS TIMESTAMP)) AS `Date`
,FROM_UNIXTIME (UNIX_TIMESTAMP(`Datetime`, 'dd MMM yyyy - HH:mm'), 'HH:mm') AS `Time`
Once all transformation has been defined you can create a new table by adding the Create Table & Using commands.
%sql
DROP TABLE IF EXISTS WorldCupMatches;
CREATE TABLE WorldCupMatches
USING csv AS
SELECT DISTINCT
CAST ( `Year` AS int ) `Year`
,`Datetime` ,`Stage` ,`Stadium` ,`City`
,`Home Team Name`
,CAST ( `Home Team Goals` AS int ) `Home Team Goals`
,CAST ( `Away Team Goals` AS int ) `Away Team Goals`
,`Away Team Name`
,`Win conditions`
,CAST ( `Attendance` AS int ) `Attendance`
,CAST ( `Half-time Home Goals` AS int ) `Half-time Home Goals`
,CAST ( `Half-time Away Goals` AS int ) `Half-time Away Goals`
,`Referee` ,`Assistant 1` ,`Assistant 2` ,CAST ( `RoundID` AS int ) AS `RoundID`
,CAST ( `MatchID` AS int ) AS `MatchID` ,`Home Team Initials` ,`Away Team Initials`
,TO_DATE(CAST(UNIX_TIMESTAMP(`Datetime`, 'dd MMM yyyy - HH:mm' ) AS TIMESTAMP)) AS `Date`
,FROM_UNIXTIME (UNIX_TIMESTAMP(`Datetime`, 'dd MMM yyyy - HH:mm'), 'HH:mm') AS `Time`
FROM tmpWorldCupMatches`
Create Credentials for Azure SQL Database
You can query and connect to existing Azure SQL Database from Azure Databricks by creating and building a JDBC URL with the relevant credentials. It is recommended and best practice to store your credentials as secrets and then use within the notebook.
%scala
// Declare the values for your Azure SQL database
val jdbcUsername = "<Username>"
val jdbcPassword = "<Password>"
val jdbcHostname = "<ServerName>.database.windows.net"
val jdbcPort = 1433
val jdbcDatabase ="<DatabaseName>"
// Create the JDBC URL without passing in the user and password parameters.
val jdbcUrl = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase}"
// Build a JDBC URL to hold the parameter/ secret import java.util.Properties
val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;"
val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")`
Perform a test operation to ensure you are connected to your Azure SQL Database, to achieve this create a DataFrame for the data from an existing table in your Azure SQL database.
%scala
// Create dataframe of SQL table
val sqlTableDF = spark.read.jdbc(jdbc_url, "<dbo.ExistingTableName>", connectionProperties)
// Run query against table for first 10 rows
sqlTableDF.show(10)
Load data to Azure SQL Database
Load data into Azure SQL Database using Spark SQL, the database table and schema will get automatically created based on the DataFrame schema.
There are two SaveMode features that determine if the existing table should be Overwrite or Append, if neither feature is specified then by default it will create a new table and throw an error message if it already exists.
%scala
// Load data to Azure SQLDB
(
spark.sql("SELECT * FROM WorldCupMatches")
.write
.mode(SaveMode.Overwrite) //**<--- Overwrite or Append the existing table**
.jdbc(jdbcUrl, "WorldCupMatches", connectionProperties)
)
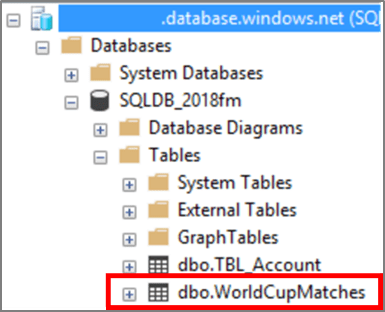
Validate Data and SQL Table
Connect to the Azure SQL Database using SQL Server Management Studios (SSMS) and validate the new dbo.WorldCupMatches table has been created and loaded successfully.
Data Ready for Analysis
Now that the data is stored in Azure SQL Database, you can connect Power BI, Excel, Analysis Service, Reporting Services to perform analysis, create models or develop reports. The following Power BI snippet is using dbo.WorldCupMatches and some additional data.
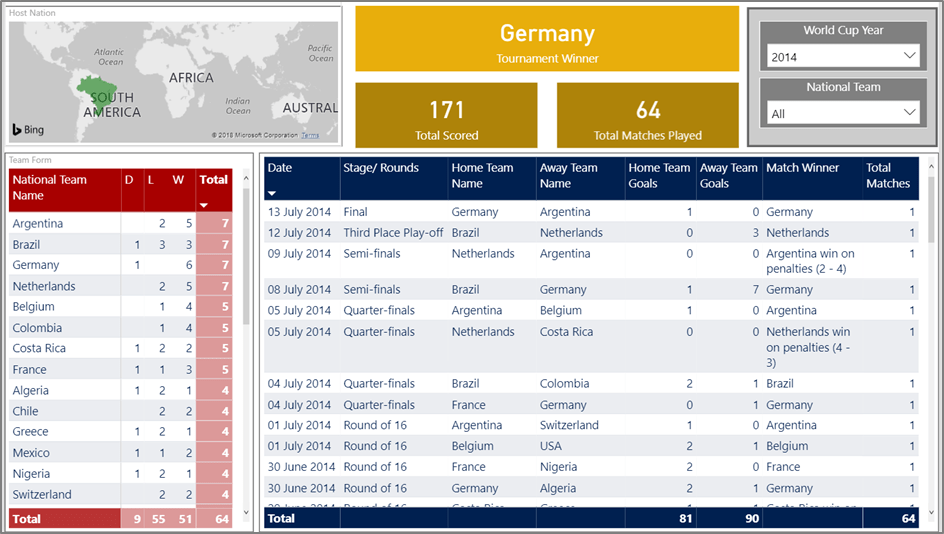
Wrap up
Databricks is a powerful tool not only can it perform data modification, cleansing and loads but it can analyse real-time streaming data from Azure Event Hub/Azure IoT Hub, be consumed directly by client tools like Power BI and perform machine learning algorithms.
Databricks fast performance, scalability, Azure Active Directory (AAD) integration, ability to use multiple and mix of coding languages also the collaborative workspaces make it a suitable choice for data engineers and data scientists.
Currently there is a lot of focus and buzz around Databricks and I can see why…
It is the next big thing in the Azure platform and I can see it potentially replacing Azure Data Lake Analytics.
I hope you found this walkthrough useful. This is just one element and approach to Azure Databricks as I have only touched the tip of the iceberg. There are many more feature and functions I have yet to cover, so watch out for more blogs until then I encourage you to try it out.
References
https://docs.microsoft.com/en-us/azure/azure-databricks/what-is-azure-databricks
https://docs.microsoft.com/en-us/azure/azure-databricks/
https://docs.azuredatabricks.net/spark/latest/spark-sql/index.html
https://docs.azuredatabricks.net/user-guide/notebooks/index.html#mixing-languages-in-a-notebook